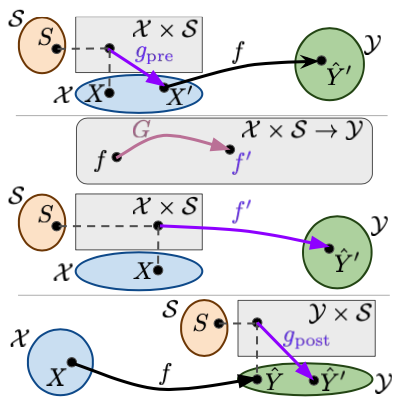
Abstract
Many methods for debiasing classifiers have been proposed, but their effectiveness in practice remains unclear. We evaluate the performance of pre-processing and post-processing debiasers for improving fairness in random forest classifiers trained on a suite of data sets. Specifically, we study how these debiasers generalize with respect to both out-of-sample test error for computing fairness–performance and fairness–fairness trade-offs, and on the change in other fairness metrics that were not explicitly optimised. Our results demonstrate that out-of-sample performance on fairness and performance can vary substantially and unexpectedly. Moreover, the variance in estimation arises from class imbalances with respect to both the outcome and the protected classes. Our results highlight the importance of evaluating out-of-sample performance in practical usage.