Bias Audit and Mitigation in Julia with Fairness.jl
Ashrya Agrawal
JuliaCon 2021
Slides also available at

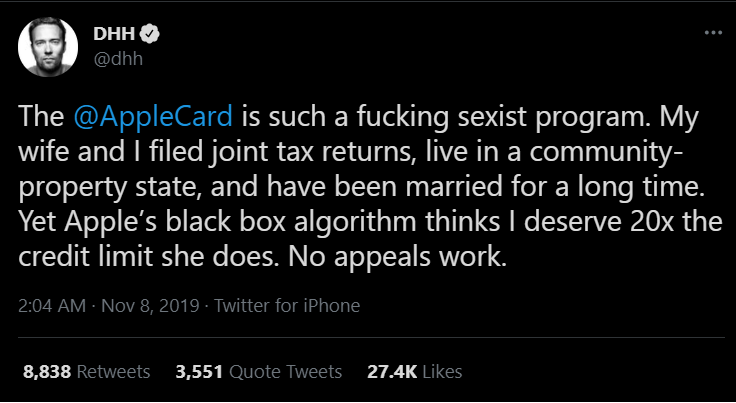





So, who's the culprit here?

So close,
yet so far :-/
Pipeline adapted from https://docs.microsoft.com/en-us/azure/architecture/data-science-process/overview
Why is there so much fuss about it?
Can't you simply remove the protected attribute from Dataset?
No!
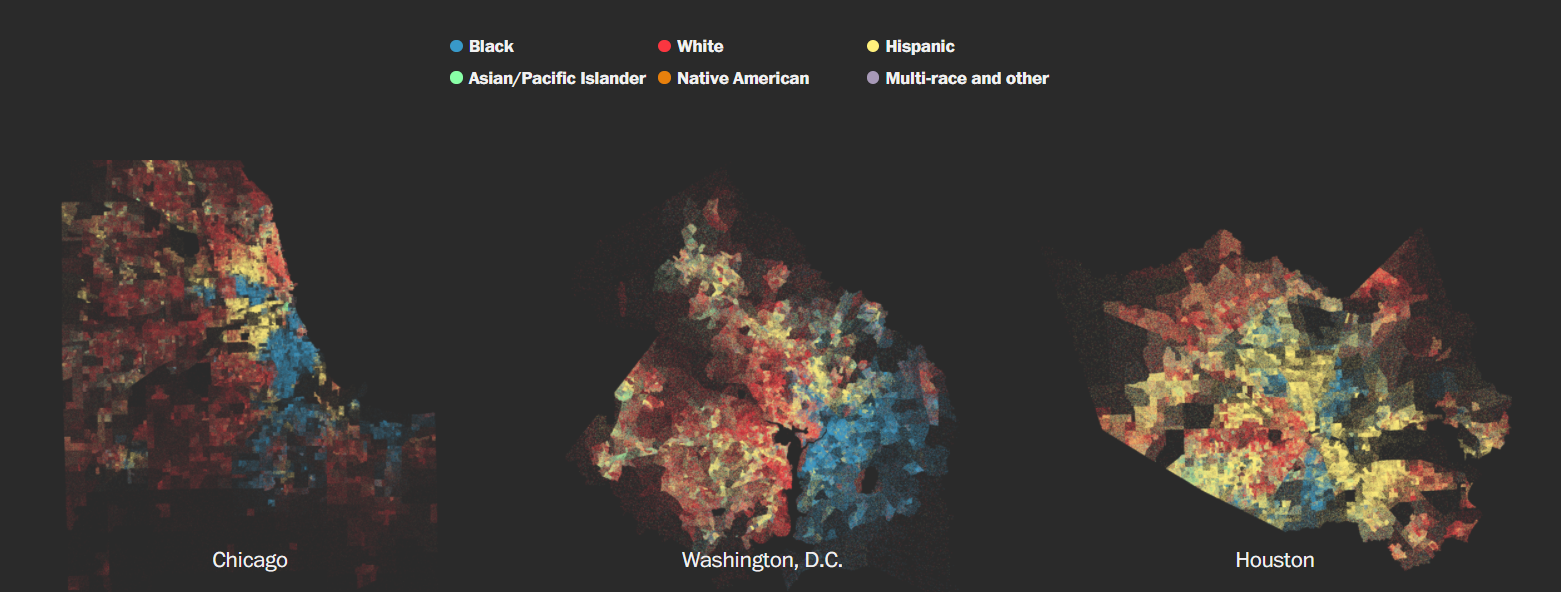
Zip codes are a proxy for race!
Protected values like race can also be indirectly inferred by the model.
- In a major healthcare algorithm, previous healthcare expenditure was serving as proxy for race, leading to reduced spending on black population.
- Spending on pedicure, beauty products, etc serves as an indicator for gender.
How hard could it really be?
1. How would you define fairness for your problem? There are numerous fairness definitions and a model fair w.r.t. one might be unfair w.r.t. other definition.
2. Fairness can result in a decrease in accuracy. How to be fair while minimizing the cost?
4. The fairness algorithm could end up making the model more unfair!!
3. Different countries have different biased groups. So our system must handle those differences.
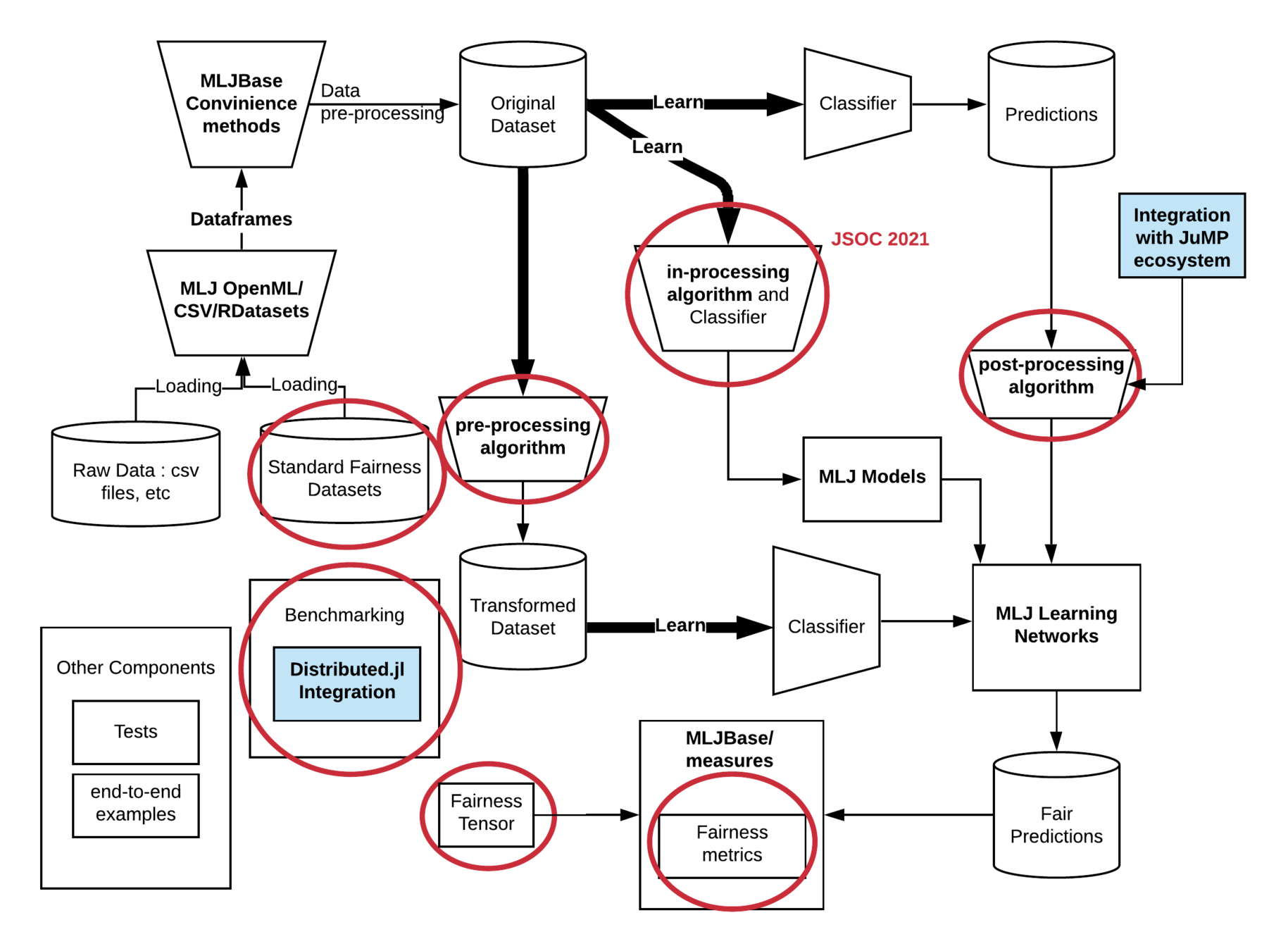
Fairness.jl
-
Bias audit and mitigation toolkit
- Collection of standard datasets
- Model-agnostic and metric-agnostic fairness algorithms
- Framework for extensive benchmarking of fairness algorithms
-
Bias can be mitigated at different steps in pipeline. Depending on this step, fairness algorithms are categorized into
- Preprocessing (modifies input/training data)
- Inprocessing (changes training procedure)
- Postprocessing (alters/flips predictions directly)
There is no one-fits-all definition for fairness
In criminal justice, you might want to use false positive rate, while in university admissions you could use recall parity
- Provides numerous observatory fairness metrics along with common aliases
TruePositive, TrueNegative, FalsePositive, FalseNegative, TruePositiveRate,
TrueNegativeRate, FalsePositiveRate, FalseNegativeRate, FalseDiscoveryRate,
Precision, NPV, TPR, TNR, FPR, FNR, FDR, PPV,
truepositive, truenegative, falsepositive, falsenegative,
true_positive, true_negative, false_positive, false_negative,
truepositive_rate, truenegative_rate, falsepositive_rate,
true_positive_rate, true_negative_rate, false_positive_rate,
falsenegative_rate, negativepredictive_value, false_negative_rate,
negative_predictive_value, positivepredictive_value, positive_predictive_value,
tpr, tnr, fpr, fnr, falsediscovery_rate, false_discovery_rate, fdr, npv, ppv,
recall, sensitivity, hit_rate, miss_rate, specificity, selectivity, f1score, fallout
PredictedPositiveRate, PP, predicted_positive_rate,
ppr, FalseOmissionRate, FOR, false_omission_rate, foar
TruePositiveRateDifference, TPRD, true_positive_rate_difference, tprd,
FalsePositiveRateDifference, FPRD, false_positive_rate_difference, fprd,
FalseNegativeRateDifference, FNRD, false_negative_rate_difference, fnrd,
FalseDiscoveryRateDifference, FDRD, false_discovery_rate_difference, fdr,
FalsePositiveRateRatio, FPRR, false_positive_rate_ratio, fprr, FalseNegativeRateRatio,
FNRR, false_negative_rate_ratio, fnrr, FalseOmissionRateRatio, FORR, false_omission_rate_ratio,
forr, FalseDiscoveryRateRatio, FDRR, false_discovery_rate_ratio, fdrr, AverageOddsDifference, AOD,
average_odds_difference, aod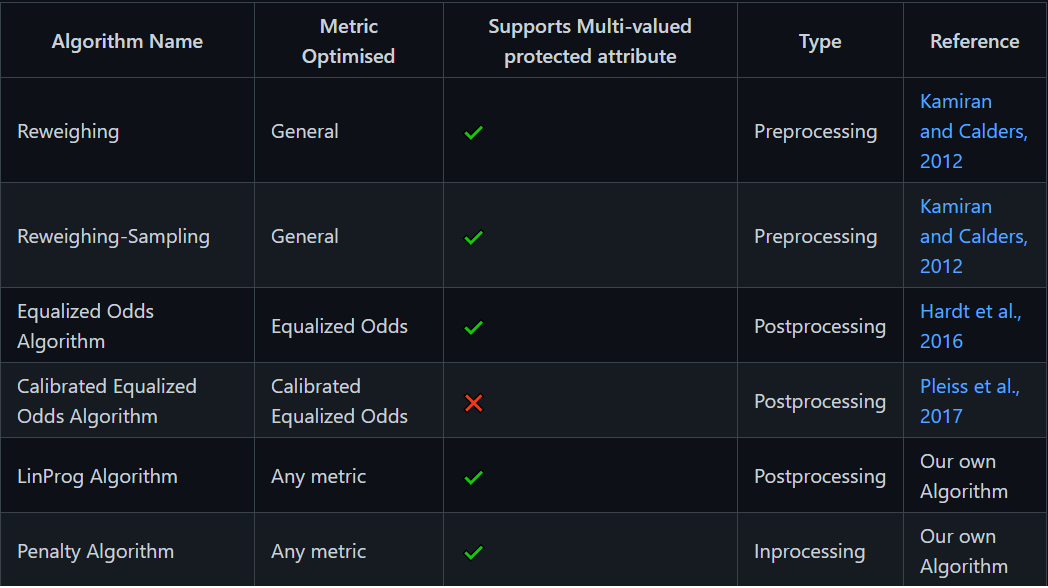
&.. Many more are in progress under JSOC '21
using Fairness, MLJ
X, y = @load_compas
@load NeuralNetworkClassifier
model = @pipeline ContinuousEncoder
NeuralNetworkClassifierevaluate(wrappedModel2,
X, y,
measures=[
Disparity(
false_positive_rate,
refGrp="Caucasian",
grp=:race),
MetricWrapper(
accuracy,
grp=:race)])wrappedModel = ReweighingSamplingWrapper(
classifier=model,
grp=:race)
wrappedModel2 = LinProgWrapper(
classifier=wrappedModel,
grp=:race,
measure=false_positive_rate)
Evaluating over 6 folds: 100%[=========================] Time: 0:03:26
(measure = [FalsePositiveRate @609_disparity, Accuracy @043],
measurement = [Dict("Caucasian" => 1.0,
"Asian" => 0.6197066145130318,
"Other" => 1.2464987907810878,
"overall" => 1.114471136936518,
"Native American" => 0.28708622756683033,
"African-American" => 1.1550342115441452,
"Hispanic" => 1.3381981057630148),
Dict("Caucasian" => 0.5639544393597365,
"overall" => 0.591280830678637,
"Asian" => 0.721031746031746,
"Other" => 0.5373151188558659,
"Native American" => 0.7666666666666666,
"African-American" => 0.6263915433136312,
"Hispanic" => 0.5145313984977116)],
per_fold = [[Dict("Caucasian" => 1.0,
"Asian" => 0.8063380281690136,
"Other" => 0.6143527833668678,
"overall" => 0.8997877996455554,
"Native American" => 0.8063380281690136,
"African-American" => 0.8875968992248061,
"Hispanic" => 0.7949811545328308),
Dict("Caucasian" => 1.0,
"Asian" => 1.3742690058479528,
"Other" => 1.0923676713150396,
"overall" => 1.0623461064943058,
"Native American" => 0.9161793372319684,
"African-American" => 1.0983934433357248,
"Hispanic" => 1.109059197701857),
Dict("Caucasian" => 1.0,
"Asian" => 0.0,
"Other" => 1.862348178137652,
"overall" => 1.4039028817789883,
"Native American" => 0.0,
"African-American" => 1.6301855326245573,
"Hispanic" => 1.8282051282051288),
Dict("Caucasian" => 1.0,
"Asian" => 0.45599999999999996,
"Other" => 1.1551999999999998,
"overall" => 1.066387434554974,
"Native American" => 0.0,
"African-American" => 1.0915275590551181,
"Hispanic" => 1.2377142857142858),
Dict("Caucasian" => 1.0,
"Asian" => 1.0816326530612241,
"Other" => 1.802721088435374,
"overall" => 1.2562119584675977,
"Native American" => 0.0,
"African-American" => 1.2457714603351067,
"Hispanic" => 1.9355531686358753),
Dict("Caucasian" => 1.0,
"Asian" => 0.0,
"Other" => 0.9520030234315947,
"overall" => 0.9981906406776871,
"Native American" => 0.0,
"African-American" => 0.9767303746895583,
"Hispanic" => 1.1236756997881119)],
[Dict("Caucasian" => 0.5367088607594936,
"overall" => 0.6145833333333334,
"Asian" => 0.75,
"Other" => 0.6615384615384615,
"Native American" => 0.6,
"African-American" => 0.6591304347826087,
"Hispanic" => 0.6296296296296297),
Dict("Caucasian" => 0.48866498740554154,
"overall" => 0.5377932232841007,
"Asian" => 0.14285714285714285,
"Other" => 0.43859649122807015,
"Native American" => 0.5,
"African-American" => 0.6037099494097807,
"Hispanic" => 0.41935483870967744),
Dict("Caucasian" => 0.6598984771573604,
"overall" => 0.635968722849696,
"Asian" => 1.0,
"Other" => 0.6142857142857143,
"Native American" => 1.0,
"African-American" => 0.6348408710217756,
"Hispanic" => 0.5402298850574713),
Dict("Caucasian" => 0.5412621359223301,
"overall" => 0.5873153779322329,
"Asian" => 0.8333333333333334,
"Other" => 0.54,
"Native American" => 1.0,
"African-American" => 0.634974533106961,
"Hispanic" => 0.4891304347826087),
Dict("Caucasian" => 0.6481012658227848,
"overall" => 0.6020851433536055,
"Asian" => 0.6,
"Other" => 0.45161290322580644,
"Native American" => 0.5,
"African-American" => 0.612736660929432,
"Hispanic" => 0.45544554455445546),
Dict("Caucasian" => 0.509090909090909,
"overall" => 0.5699391833188532,
"Asian" => 1.0,
"Other" => 0.5178571428571429,
"Native American" => 1.0,
"African-American" => 0.6129568106312292,
"Hispanic" => 0.5533980582524272)]],
per_observation = [missing, missing],
fitted_params_per_fold =
[(fitresult = [[[0.4811044092793654,
0.06147223597164733,
0.5278109857658507,
0.3046377224179335,
0.018528882735561157,
0.0002801118924418782],
[0.303965142150392,
0.6904750642640544,
0.4427945875213156,
0.3431853738004899,
0.30956315697359355,
0.2567525971191049]],
(predict = Node{Machine{Pipeline402}} @279,),
[0, 1]],),
(fitresult = [[[0.5588051604392756,
0.9556043818169735,
0.30639748848311293,
0.348612754649609,
0.4365068766941083,
0.4043445298515746],
[0.6882039866276403,
0.9920755748997635,
0.5849444936357443,
0.6792907535014425,
0.6099969142272105,
0.7289919307542917]],
(predict = Node{Machine{Pipeline402}} @725,),
[0, 1]],),
(fitresult = [[[0.40708147682432333,
0.5472590139999254,
0.00955587838555424,
0.5293113191526267,
0.3552522591071384,
0.4478887177634008],
[0.2977844036279724,
0.7682509248063255,
0.05509930942045507,
0.49756351369147145,
0.035100375228515814,
0.49015757611103855]],
(predict = Node{Machine{Pipeline402}} @689,),
[0, 1]],),
(fitresult = [[[0.999925812049108,
0.9802483169919184,
0.2054159403529095,
0.839965280106501,
0.49298770252097157,
0.8249553395297932],
[0.4922045406296876,
0.5332368553861355,
0.40410283450061674,
0.6090512967687178,
0.5041069457300733,
0.6026248260664203]],
(predict = Node{Machine{Pipeline402}} @717,),
[0, 1]],),
(fitresult = [[[0.2500591412753533,
0.14463186095615735,
0.000675110602308825,
0.996812375697747,
0.06304608072440798,
0.9883761052997926],
[0.3944706843277948,
0.6190896139428711,
0.3552048695305871,
0.8320196710497626,
0.3052623265756199,
0.7936049831530788]],
(predict = Node{Machine{Pipeline402}} @829,),
[0, 1]],),
(fitresult = [[[0.518636286340774,
0.1877741203729742,
0.5192511278401304,
0.9747796181144148,
0.06419120209953995,
0.40781493654940687],
[0.4702239197114813,
0.6825522720605911,
0.5473230730072678,
0.7427667489585572,
0.22103521074555144,
0.5441393848904584]],
(predict = Node{Machine{Pipeline402}} @768,),
[0, 1]],)],
report_per_fold = [nothing, nothing, nothing, nothing, nothing, nothing])Fairness.jl workflow
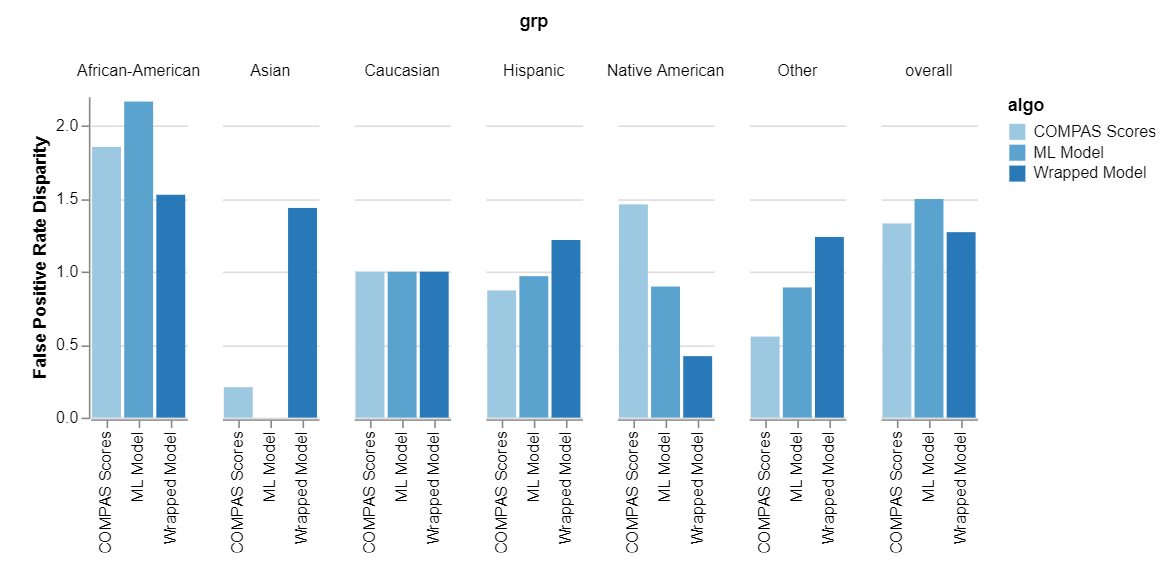
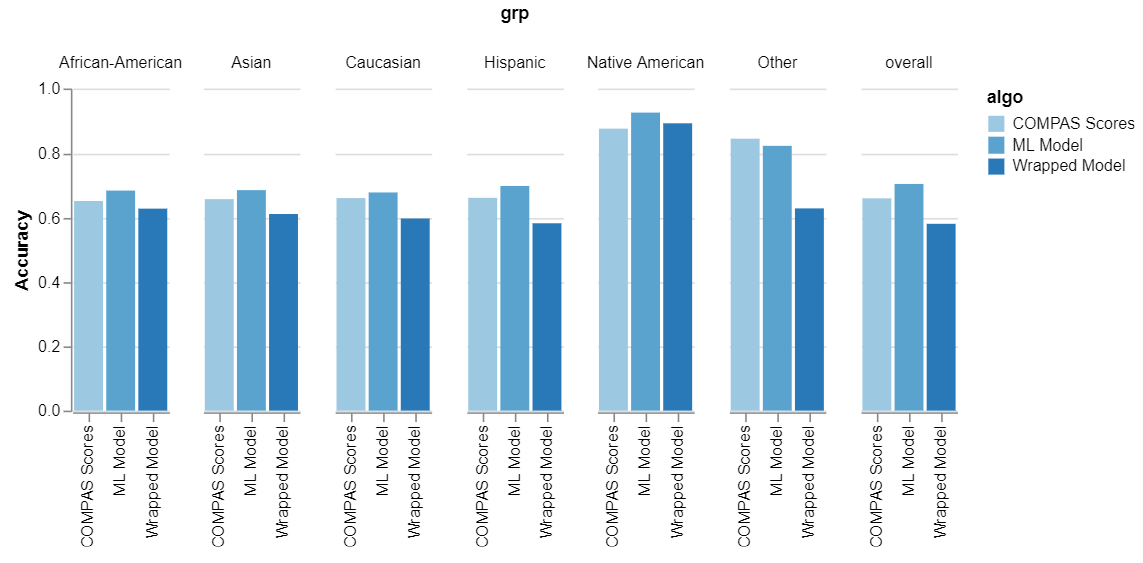
Fairness
Accuracy
But decrease is low
Finer control is also possible
train, test = partition(
eachindex(y), 0.7, shuffle=true)
mach = machine(wrappedModel2, X, y)
fit!(mach, rows=train)
ŷ = predict(mach, rows=test)
disparity(
[accuracy, false_positive_rate],
ft, refGrp="Caucasian",
func=(x, y)->(x-y)/y
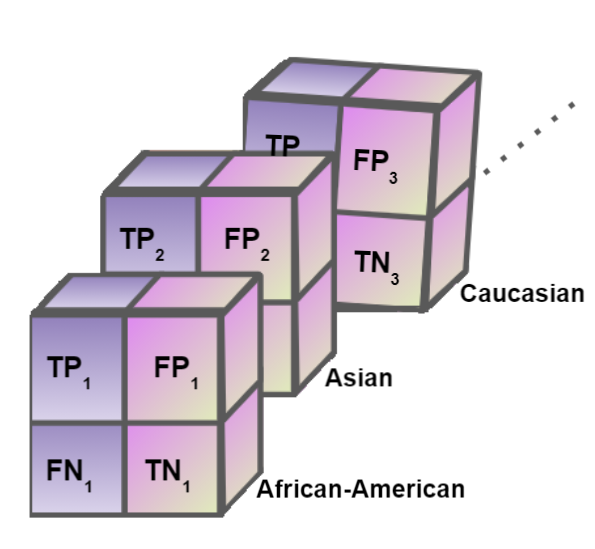
)ft = fair_tensor(ŷ, y[test],
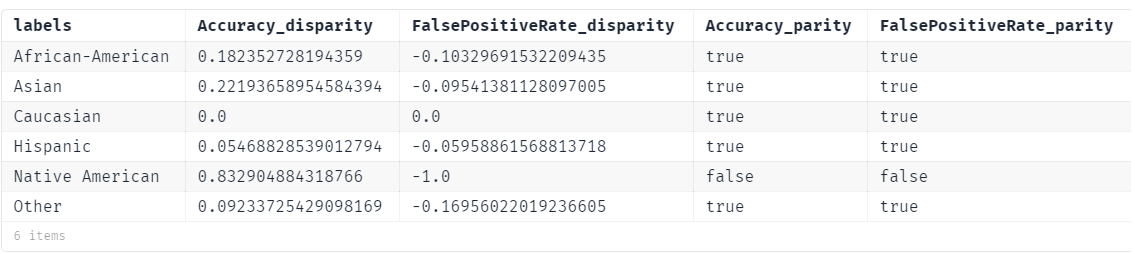
X[test, :race])parity(df_disparity,
func= (x) -> abs(x)<0.4
)
Our research on generalization in fairness
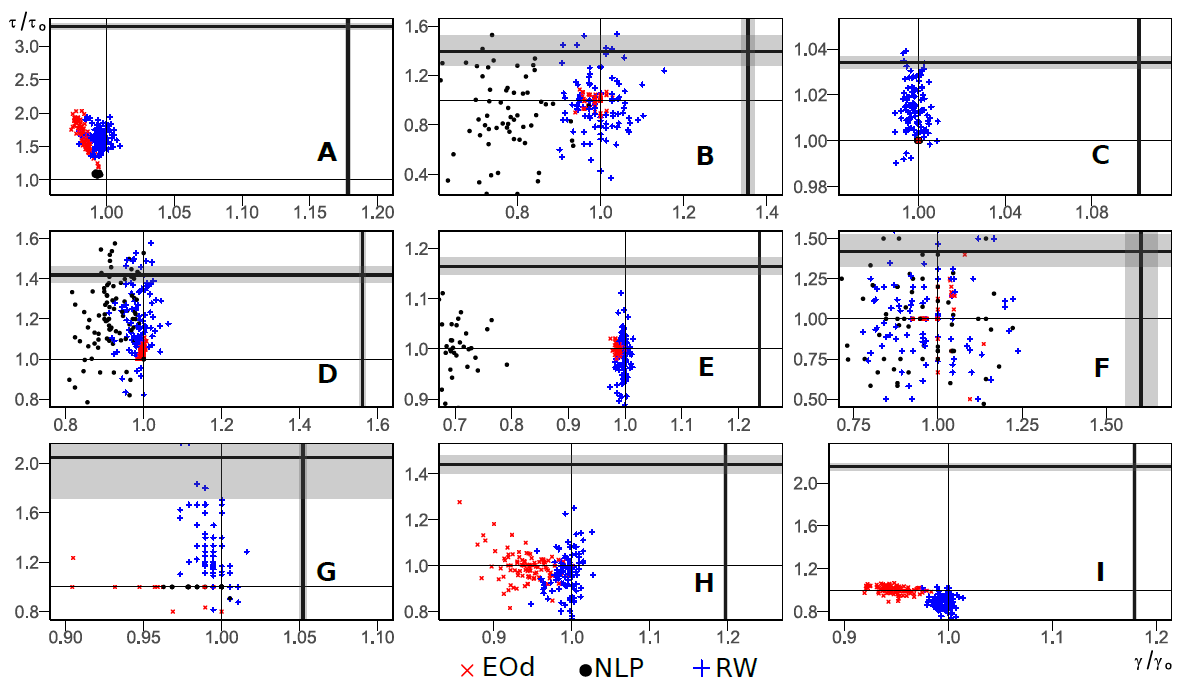
Plots of fairness ratios (vertical axes) against accuracy ratios(horizontal axes) using random forest classifiers, showing the failure in OOD generalization of fairness algorithms
For details refer https://arxiv.org/abs/2011.02407
How Julia Ecosystem helped us?
- Speed (goes without saying), flexibility and composability (dispatch).
-
We leverage MLJ interfaces and structure, which enables us to study 150+ ML models with various fairness algorithms and datasets.
- JuMP ecosystem helped in the easy formulation of optimization problems with Fairness constraints.
- For our research, we needed to create an extensive benchmark of fairness algorithms. Distributed computing was made very easy with Distributed.jl
Outlook

- JSOC '21 by Sumantrak
- Inprocessing algorithms
- Plotting library for visualization of fairness performance
- &.. More pre-processing and post-processing algorithms
- GSOC' 21 by Archana
- Leverage Omega.jl and CausalInference.jl to create julia package for causal analysis of fairness
- Tools for Counterfactual fairness